Data Modules¶
This note will introduce the unified dataset interface defined by Open-ReID, and the whole data loader system that samples data efficiently.
Unified Data Format¶
There are many existing person re-identification datasets, each with its own data format and split protocols. This makes conducting experiments on these datasets a tedious and error-prone work. To solve this problem, Open-ReID defines a unified dataset interface. By converting the raw dataset into this unified format, we can significantly simplify the code for training and evaluation with the formatted data.
Every dataset will be organized as a directory like
cuhk03
├── raw/
├── images/
├── meta.json
└── splits.json
where raw/ stores the original dataset files, images/ contains all the
renamed image files in the format of:
'{:08d}_{:02d}_{:04d}.jpg'.format(person_id, camera_id, image_id)
where all the ids are indexed from 0.
meta.json contains all the person identities of the dataset, which is a list in the structure of:
"identities": [
[ # the first identity, person_id = 0
[ # camera_id = 0
"00000000_00_0000.jpg",
"00000000_00_0001.jpg"
],
[ # camera_id = 1
"00000000_01_0000.jpg",
"00000000_01_0001.jpg",
"00000000_01_0002.jpg"
]
],
[ # the second identity, person_id = 1
[ # camera_id = 0
"00000001_00_0000.jpg"
],
[ # camera_id = 1
"00000001_01_0000.jpg",
"00000001_01_0001.jpg",
]
],
...
]
Each dataset may define multiple training / test data splits. They are listed in
splits.json, where each split defines three subsets of person identities:
{
"trainval": [0, 1, 3, ...], # person_ids for training and validation
"gallery": [2, 4, 5, ...], # for test gallery, non-overlap with trainval
"query": [2, 4, ...], # for test query, a subset of gallery
}
Data Loading System¶
The objective of the data loading system is to sample mini-batches efficiently from the dataset. In our design, it consists of four components, namely Dataset, Sampler, Preprocessor, and Data Loader. Their relations are depicted in the figure below.
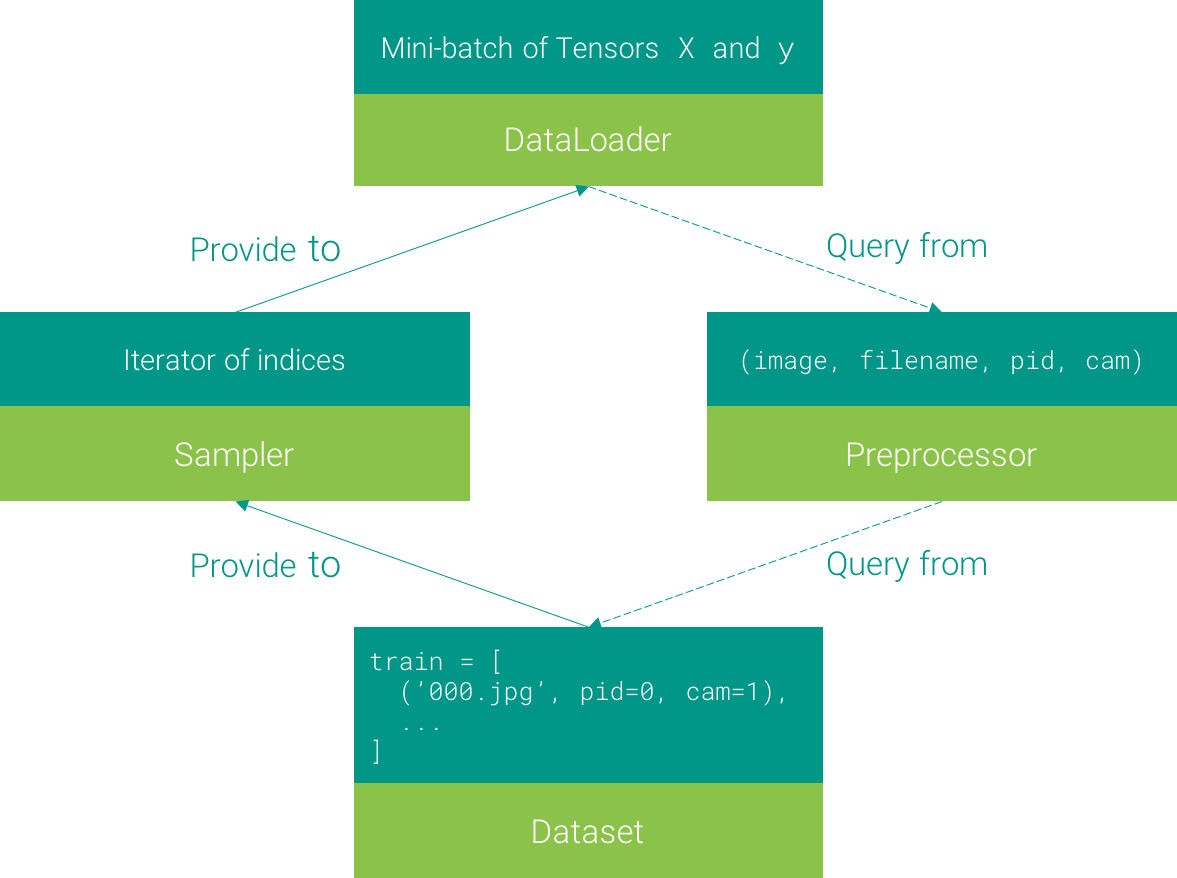
A Dataset is a list of items (filename, person_id, camera_id). A Sampler is an iterator that each time provides an index. At the top, we adopt the torch.utils.data.DataLoader to load mini-batches using multi-processing. It queries the data at given index from a Preprocessor, which takes the index as input, loading the corresponding image (with transformations), and returns a tuple of (image, filename, person_id, camera_id).